tukey_hsd#
- scipy.stats.tukey_hsd(*samples, equal_var=True)[source]#
Perform Tukey’s HSD test for equality of means over multiple treatments.
Tukey’s honestly significant difference (HSD) test performs pairwise comparison of means for a set of samples. Whereas ANOVA (e.g.
f_oneway) assesses whether the true means underlying each sample are identical, Tukey’s HSD is a post hoc test used to compare the mean of each sample to the mean of each other sample.The null hypothesis is that the distributions underlying the samples all have the same mean. The test statistic, which is computed for every possible pairing of samples, is simply the difference between the sample means. For each pair, the p-value is the probability under the null hypothesis (and other assumptions; see notes) of observing such an extreme value of the statistic, considering that many pairwise comparisons are being performed. Confidence intervals for the difference between each pair of means are also available.
- Parameters:
- *samplesarray_like
The sample measurements for each group. There must be at least two arguments.
- equal_varbool, optional
If True (default) and equal sample size, perform Tukey-HSD test [6]. If True and unequal sample size, perform Tukey-Kramer test [4]. If False, perform Games-Howell test [7], which does not assume equal variances.
- Returns:
- result
TukeyHSDResultinstance The return value is an object with the following attributes:
- statisticfloat ndarray
The computed statistic of the test for each comparison. The element at index
(i, j)is the statistic for the comparison between groupsiandj.- pvaluefloat ndarray
The computed p-value of the test for each comparison. The element at index
(i, j)is the p-value for the comparison between groupsiandj.
The object has the following methods:
- confidence_interval(confidence_level=0.95):
Compute the confidence interval for the specified confidence level.
- result
See also
dunnettperforms comparison of means against a control group.
Notes
The use of this test relies on several assumptions.
The observations are independent within and among groups.
The observations within each group are normally distributed.
The distributions from which the samples are drawn have the same finite variance.
The original formulation of the test was for samples of equal size drawn from populations assumed to have equal variances [6]. In case of unequal sample sizes, the test uses the Tukey-Kramer method [4]. When equal variances are not assumed (
equal_var=False), the test uses the Games-Howell method [7].References
[1]NIST/SEMATECH e-Handbook of Statistical Methods, “7.4.7.1. Tukey’s Method.” https://www.itl.nist.gov/div898/handbook/prc/section4/prc471.htm, 28 November 2020.
[2]Abdi, Herve & Williams, Lynne. (2021). “Tukey’s Honestly Significant Difference (HSD) Test.” https://personal.utdallas.edu/~herve/abdi-HSD2010-pretty.pdf
[3]“One-Way ANOVA Using SAS PROC ANOVA & PROC GLM.” SAS Tutorials, 2007. https://www.stattutorials.com/SAS/TUTORIAL-PROC-GLM.htm
[4] (1,2)Kramer, Clyde Young. “Extension of Multiple Range Tests to Group Means with Unequal Numbers of Replications.” Biometrics, vol. 12, no. 3, 1956, pp. 307-310. https://www.jstor.org/stable/3001469
[5]NIST/SEMATECH e-Handbook of Statistical Methods, “7.4.3.3. The ANOVA table and tests of hypotheses about means” https://www.itl.nist.gov/div898/handbook/prc/section4/prc433.htm, 2 June 2021.
[6]Tukey, John W. “Comparing Individual Means in the Analysis of Variance.” Biometrics, vol. 5, no. 2, 1949, pp. 99-114. https://www.jstor.org/stable/3001913
[7] (1,2)P. A. Games and J. F. Howell, “Pairwise Multiple Comparison Procedures with Unequal N’s and/or Variances: A Monte Carlo Study,” Journal of Educational Statistics, vol. 1, no. 2, pp. 113-125, Jun. 1976. DOI:10.3102/10769986001002113.
Examples
Here are some data comparing the time to relief of three brands of headache medicine, reported in minutes. Data adapted from [3].
>>> import numpy as np >>> from scipy.stats import tukey_hsd >>> group0 = [24.5, 23.5, 26.4, 27.1, 29.9] >>> group1 = [28.4, 34.2, 29.5, 32.2, 30.1] >>> group2 = [26.1, 28.3, 24.3, 26.2, 27.8]
We would like to see if the means between any of the groups are significantly different. First, visually examine a box and whisker plot.
>>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(1, 1) >>> ax.boxplot([group0, group1, group2]) >>> ax.set_xticklabels(["group0", "group1", "group2"]) >>> ax.set_ylabel("mean") >>> plt.show()
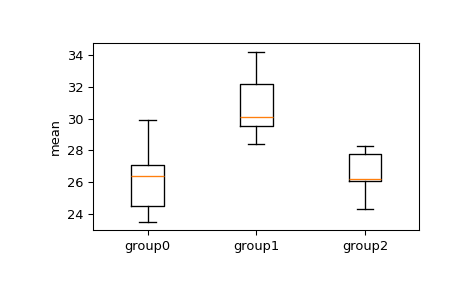
From the box and whisker plot, we can see overlap in the interquartile ranges group 1 to group 2 and group 3, but we can apply the
tukey_hsdtest to determine if the difference between means is significant. We set a significance level of .05 to reject the null hypothesis.>>> res = tukey_hsd(group0, group1, group2) >>> print(res) Pairwise Group Comparisons (95.0% Confidence Interval) Comparison Statistic p-value Lower CI Upper CI (0 - 1) -4.600 0.014 -8.249 -0.951 (0 - 2) -0.260 0.980 -3.909 3.389 (1 - 0) 4.600 0.014 0.951 8.249 (1 - 2) 4.340 0.020 0.691 7.989 (2 - 0) 0.260 0.980 -3.389 3.909 (2 - 1) -4.340 0.020 -7.989 -0.691
The null hypothesis is that each group has the same mean. The p-value for comparisons between
group0andgroup1as well asgroup1andgroup2do not exceed .05, so we reject the null hypothesis that they have the same means. The p-value of the comparison betweengroup0andgroup2exceeds .05, so we accept the null hypothesis that there is not a significant difference between their means.We can also compute the confidence interval associated with our chosen confidence level.
>>> group0 = [24.5, 23.5, 26.4, 27.1, 29.9] >>> group1 = [28.4, 34.2, 29.5, 32.2, 30.1] >>> group2 = [26.1, 28.3, 24.3, 26.2, 27.8] >>> result = tukey_hsd(group0, group1, group2) >>> conf = res.confidence_interval(confidence_level=.99) >>> for ((i, j), l) in np.ndenumerate(conf.low): ... # filter out self comparisons ... if i != j: ... h = conf.high[i,j] ... print(f"({i} - {j}) {l:>6.3f} {h:>6.3f}") (0 - 1) -9.480 0.280 (0 - 2) -5.140 4.620 (1 - 0) -0.280 9.480 (1 - 2) -0.540 9.220 (2 - 0) -4.620 5.140 (2 - 1) -9.220 0.540